

When we are storing data in our system be it in RDBMS/DBMS/NOSQL using HDD/SSD/Tapes we are always storing it as byte and yes a byte is a unit of storage capable of holding a single character, and the same byte grows in KB, MB..TB…. and so on.
Have you given it a thought on how do you actually store these bytes because the only way to manage large quantities of data is to make them addressable in larger pieces, above the byte level. For that, we need a mechanism to address these large lumps of data by some kind of name or handle, organize it for storage on external storage devices with different characteristics, and provide protocols/API that allow us to programmatically write, find, and read it.
Just as there are different kind of information available to each one of us, there are different types of storage medium available to address them. Storage devices save information in three different ways: Blocks, Files and Objects. With the advent of Cloud choosing which stack to use based on how data is saved or retrieved have considerable significance on your IT system.Lets start with first on the list and move to others then.
Block Storage
Block storage file systems are the most basic type of file storage system. Data is stored in numbered blocks, identical in size. This means a single file can take up several blocks of data to write. Information is recalled and organized by a SAN (Storage Area Network).
With block-level storage systems, the SAN is extremely important, because this software maintains a record of where the data lives, knows how to retrieve it and can also organize it in a way the user understands. For this reason, block storage systems are usually used in databases and other performance-oriented applications. AWS EBS stores data using block storage
Object Storage
In an object storage system, files and other media are saved as individual objects. Each object is assigned an ID number. The system generates a unique identifier number for each file based on its content and metadata. The ID is very important, because that’s how applications and other software find the objects in the system.
Objects are stored on any and all available disk space. But object storage systems aren’t capable of updating files, so every time a user alters a document, the file is saved as a completely new object. As a result, object storage systems are an ideal choice for archiving. AWS S3 stores data using Object storage mechanism and every object can by retrieved using its object key ID
File Storage
Simpler end of the storage solution is file storage. File storage provides one centralized location for your enterprise to store data. It uses metadata and directories to organize files, which makes it an easy solution for those looking to store large data .
The hierarchical nature of file storage align it well with real-life counterpart, the filing cabinet where you have specific drawers, and folders within it. To quickly locate your file, you would first need to be made aware of which drawer and which folder you need to look for. The disadvantages of this is that the more data you add, the more tedious it becomes to search through each individual drawer and folder.
Many applications need to access and share the same files, making file storage the natural choice. This specific type of storage is often supported by a Network Attached Storage (NAS) server. AWS solutions such as the Amazon Elastic File System (EFS) are ideal for large content repositories, media stores, or directories.
Below is a brief comparison of these storage types based on many factors
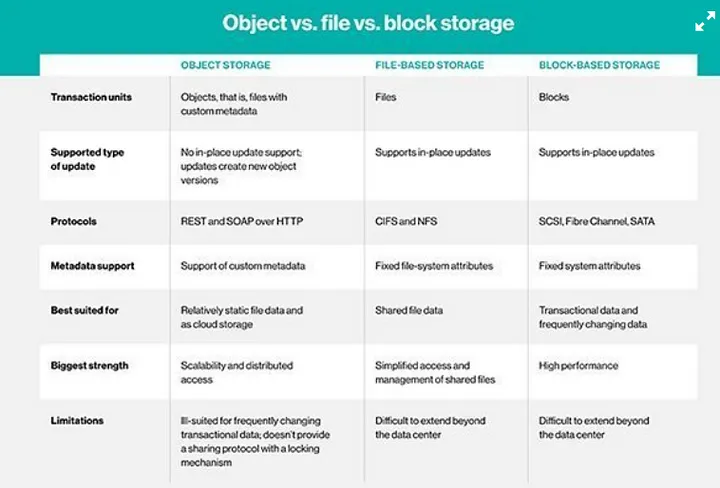
ALL the best for choosing the right storage for your requirement


